使用Cloudflare R2对象存储作为网站图床

greatqian•2025-08-20 02:52
3 min read
在搭建网站的过程中,经常需要上传一些图片。如果把所有图片全部放在代码目录里面会导致项目非常大。而且vercel的流量有限制,图片是流量消耗大户,有时候一张高质量图片可能比整个站点的页面代码文件体积都大。另外,如果手动将一张张需要用到的图片放到public下的图片目录里,然后一个个重命名,并且在img的src中配置指向这个本地图片路径,也是非常耗时间的麻烦事情。
尤其是如果需要实现博客文章内容嵌入图片的话,图床更是必不可少的。直接上传一张图片到图床,然后接口返回图片url地址,md编辑器自动添加为md格式的图片链接。这样就能够随时随地方便的在文章中插入图片了。
创建并配置R2存储桶
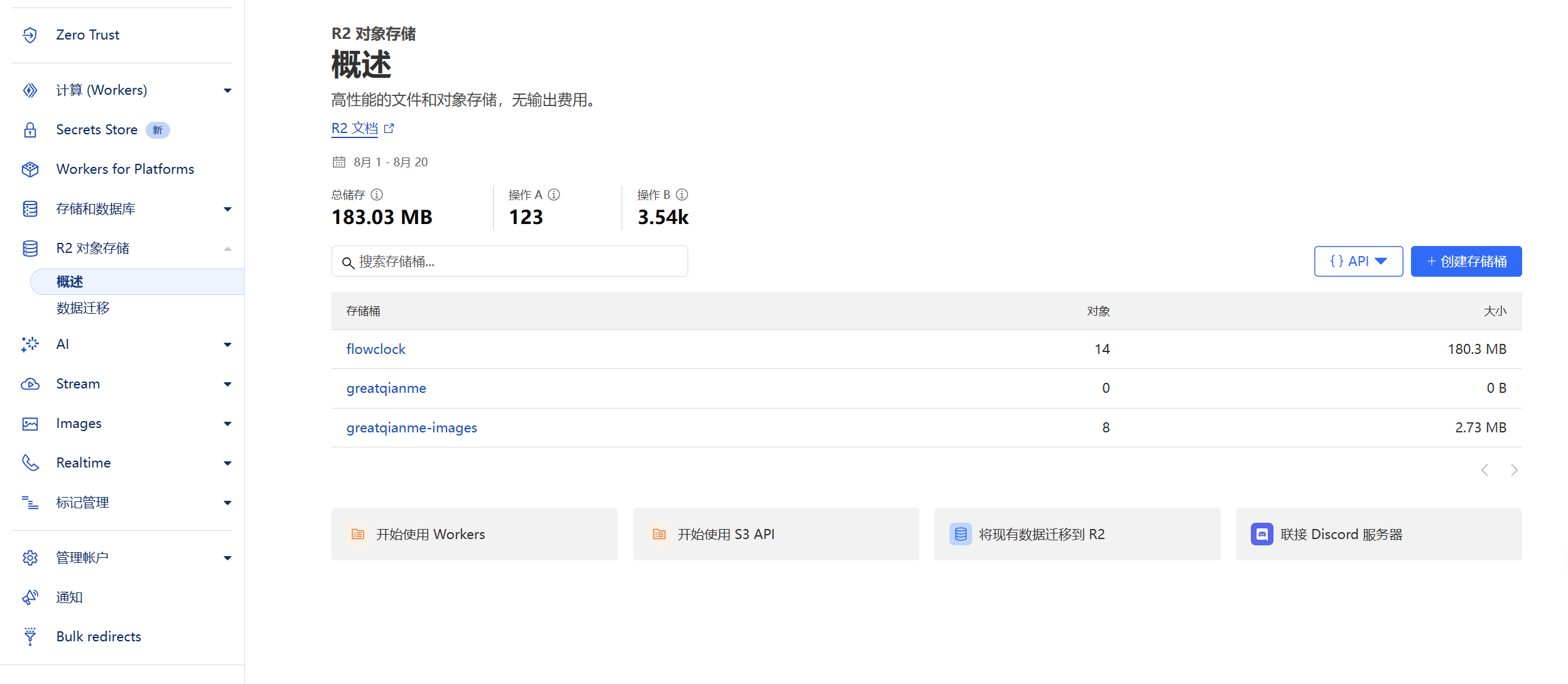
打开Cloudflare控制台,进入R2存储页面
点击新建存储桶
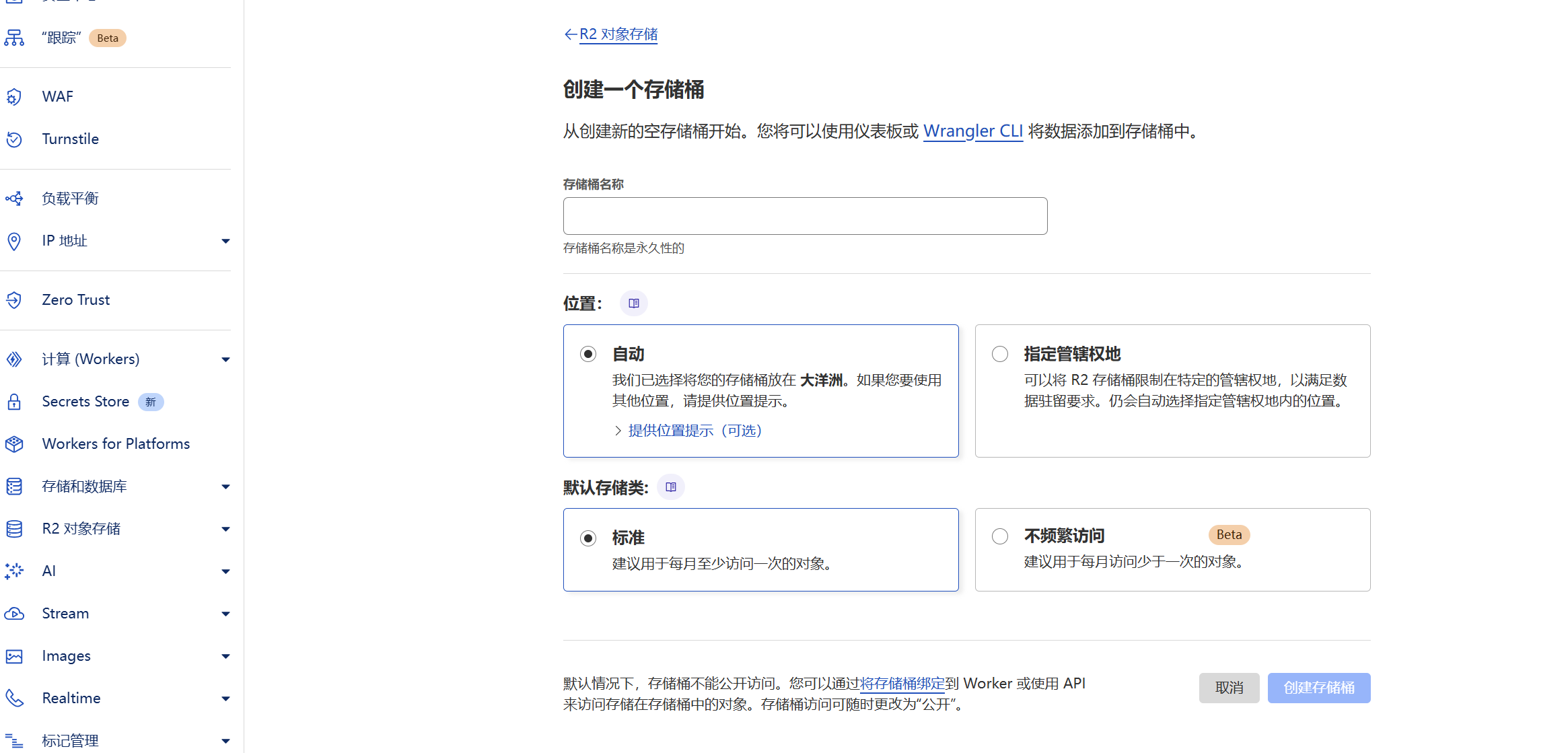
接下来就可以拖入文件上传到存储桶了
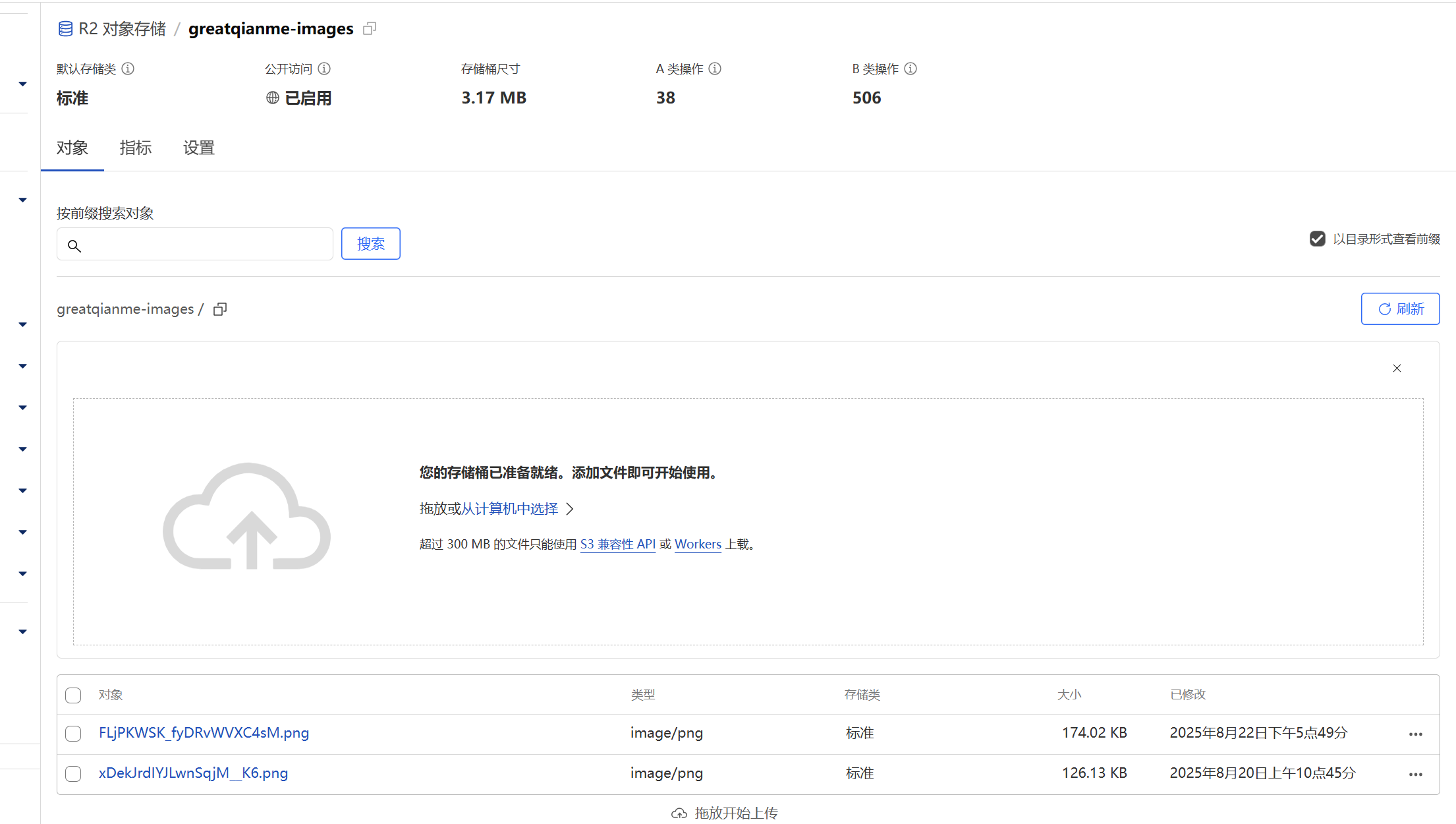
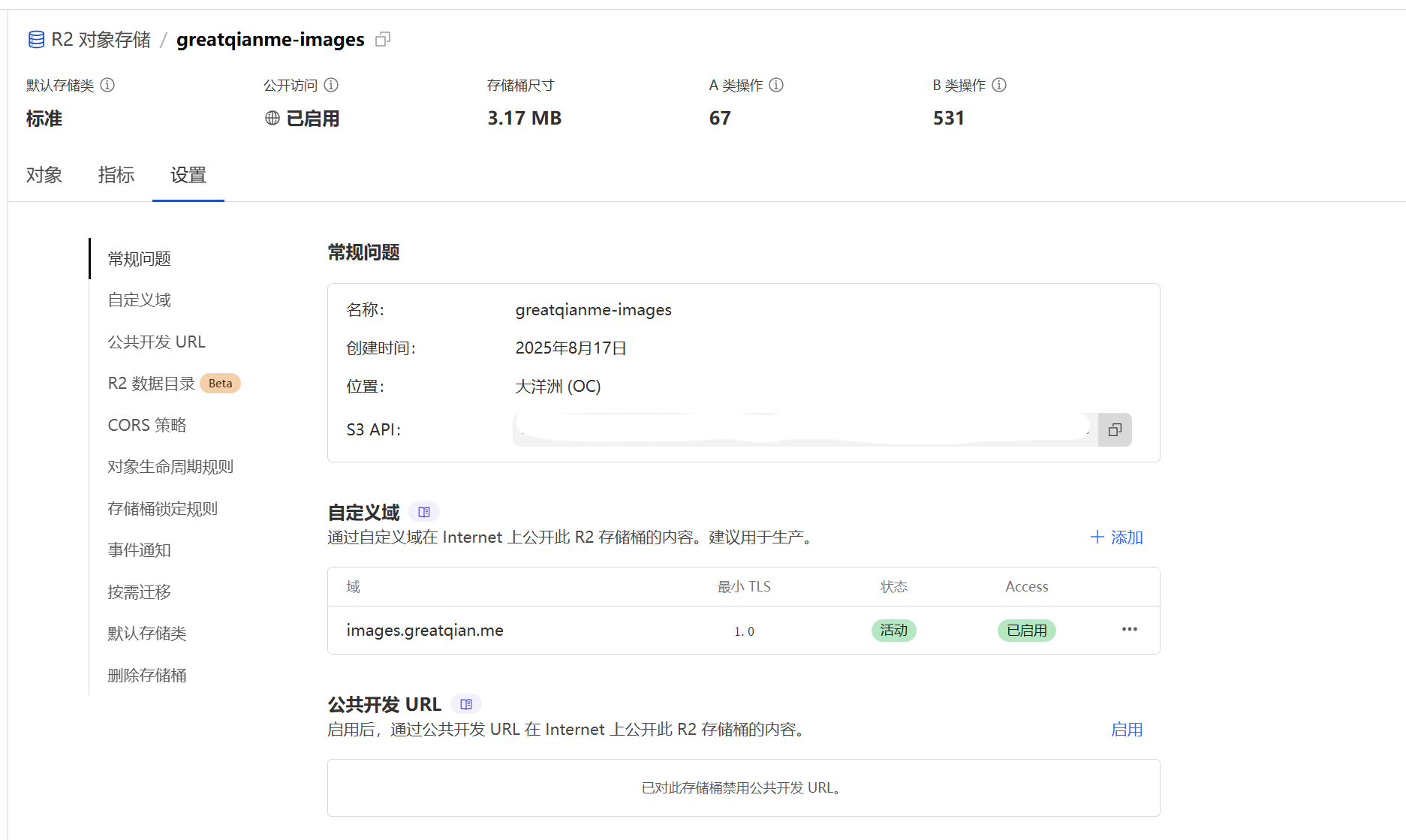
如果有自己的域名的话,可以使用子域名,否则启用公共开发url作为访问基础路径
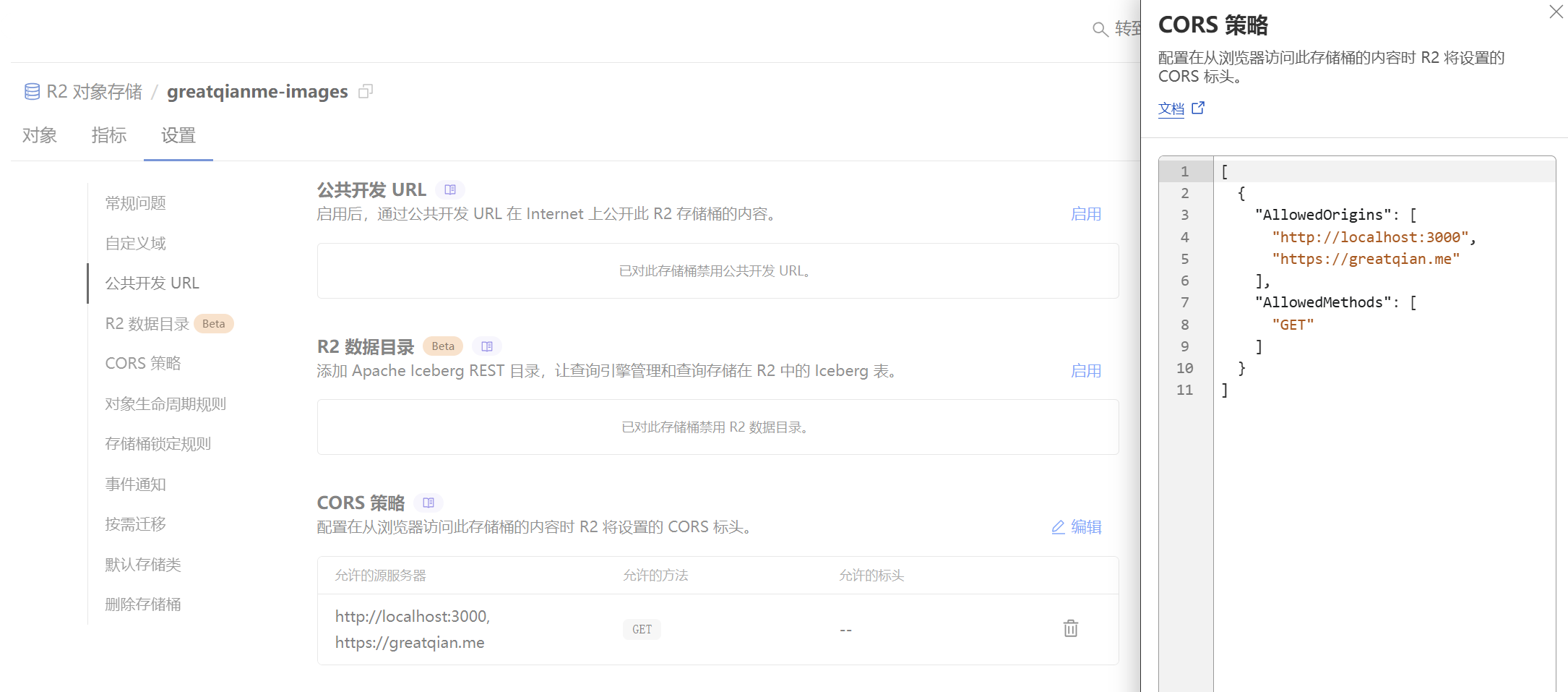
配置CORS策略,让图片能够被网站跨域访问(需要使用JS操作图片)
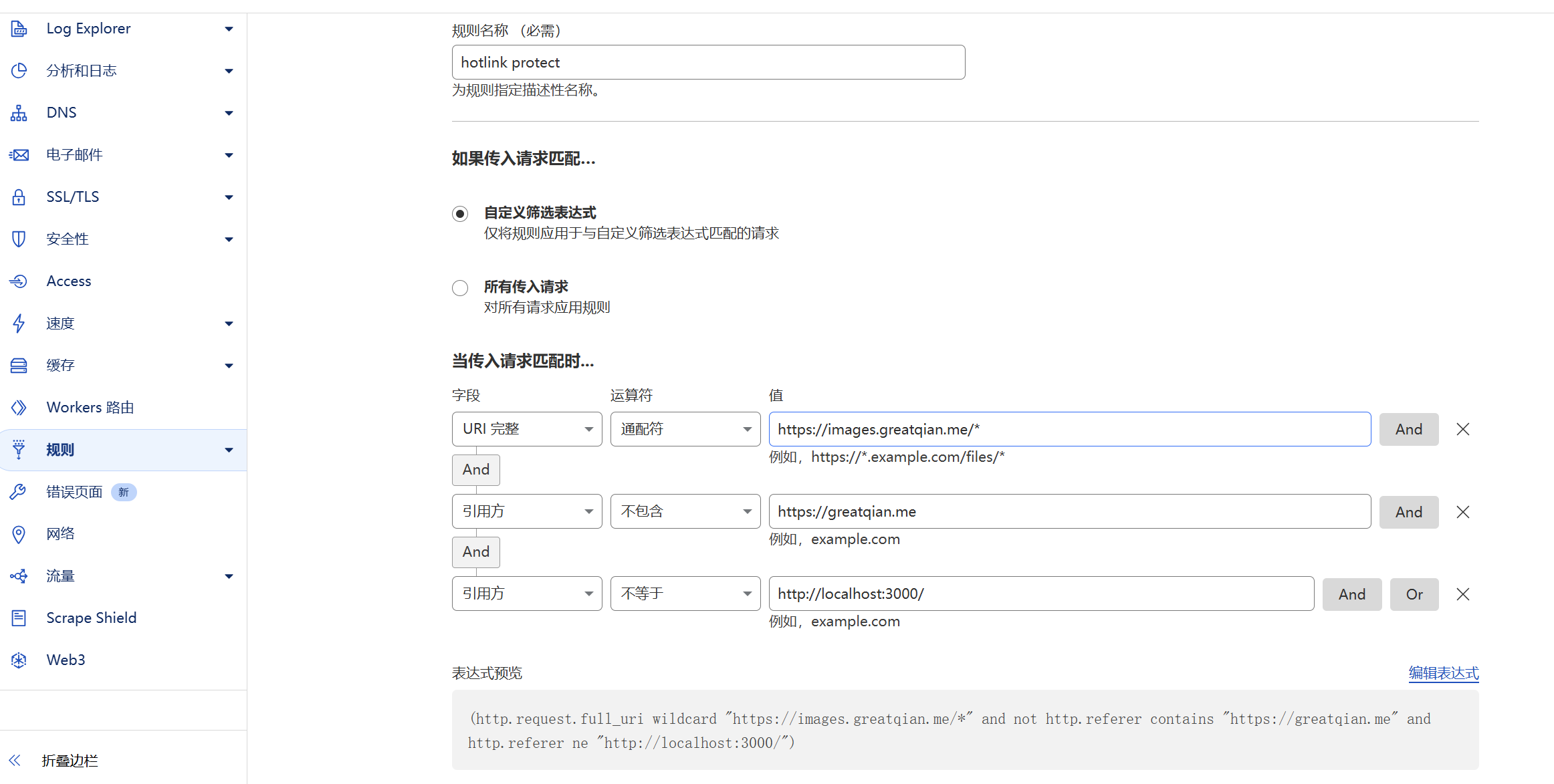
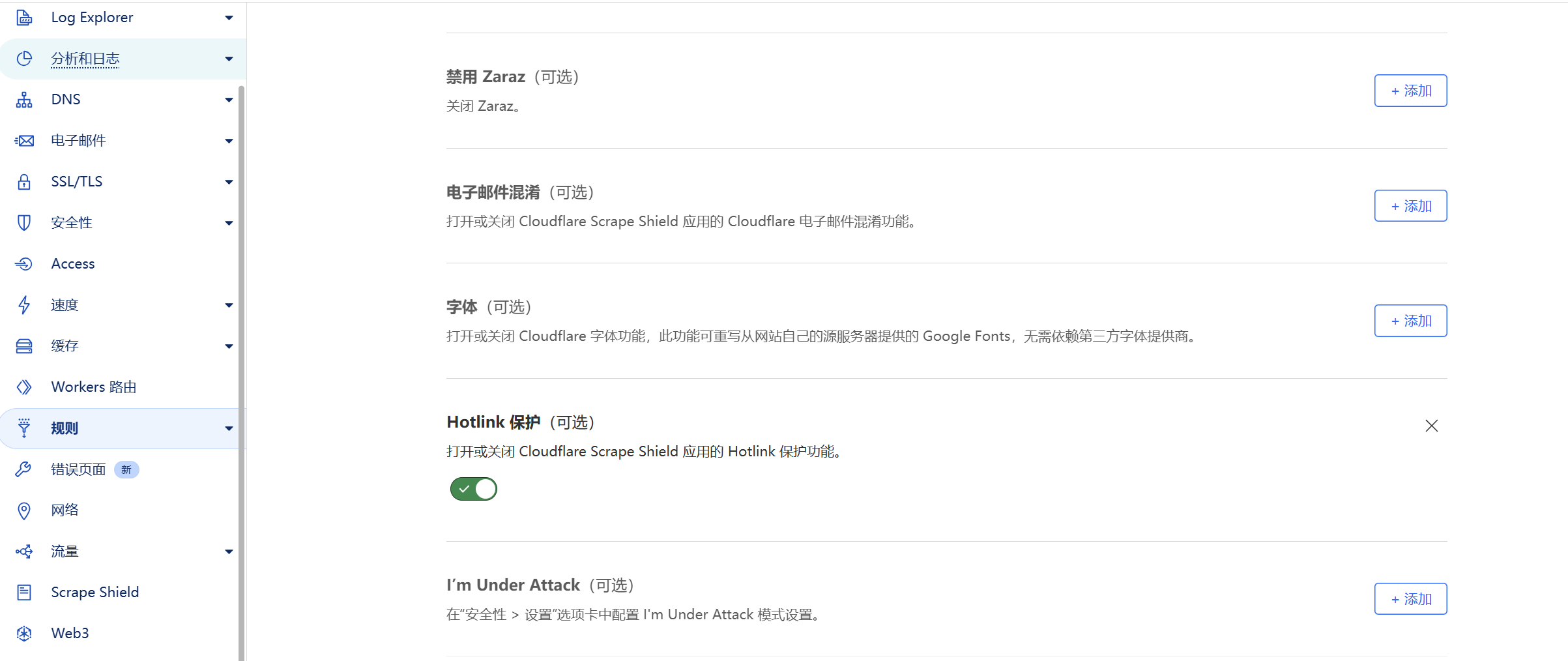
另外,如果R2使用的是自己的子域名,而且站点的Hotlink防盗链保护开启了的话,主域名网站也无法直接引用子域名的图片。可以将默认的Hotlink关闭
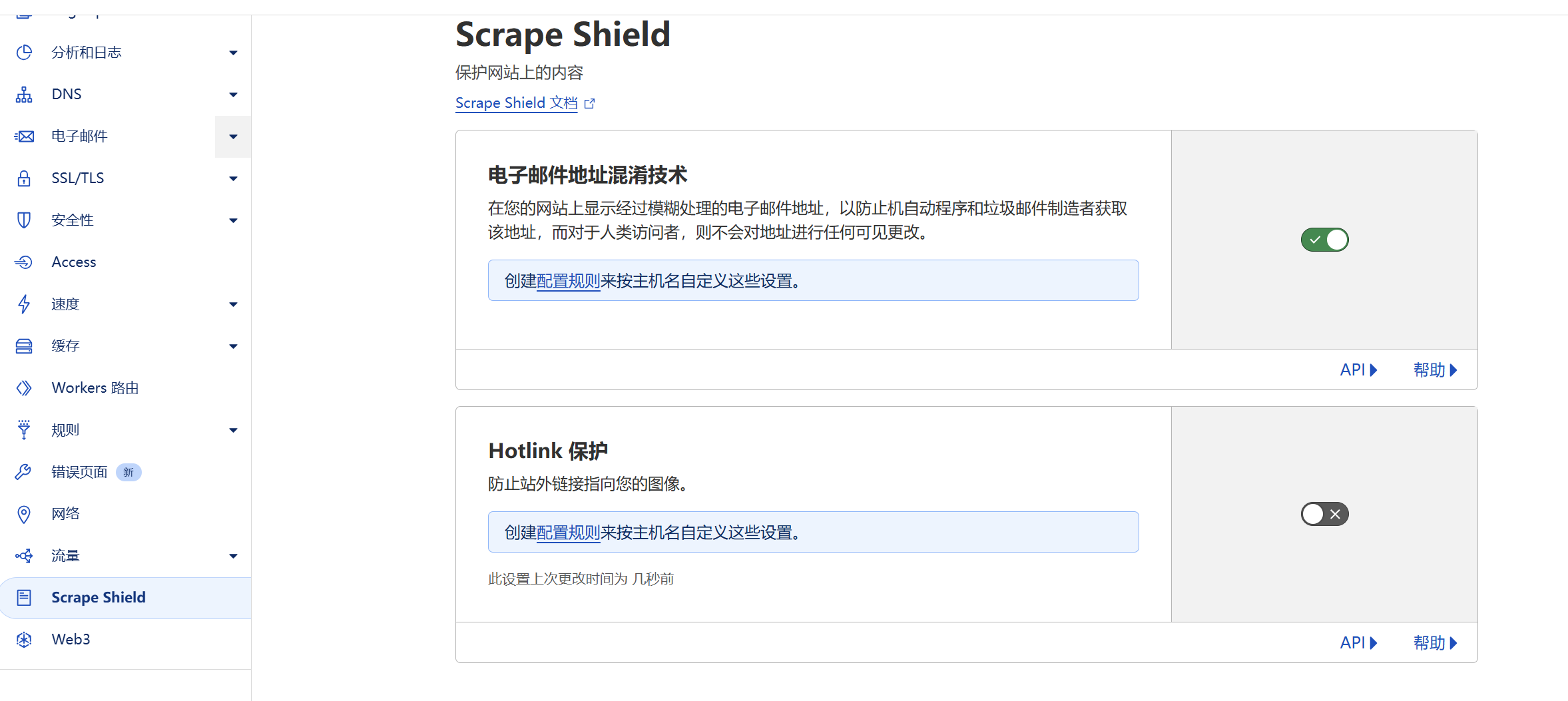
然后在规则页面手动配置Hotlink规则,只对不符合条件的refer域名启用防盗链